SPARQL Trigger Processor¶
What is the SPARQL Trigger Processor?¶
The SPARQL Trigger Processor is a CM-Well agent for running SPARQL queries and constructs periodically, for the purposes of creating materialized views of CM-Well infotons. A materialized view is a "flattened" version of data whose original source included high levels of pointer redirection before arriving at data. (The materialized view may also be enriched with data from other infotons.)
The SPARQL Trigger Processor creates one or more sensors. Each sensor periodically runs a query on a specified path in CM-Well, to detect changes to infotons under that path that have changed since the previous query. When changes are detected, the sensor reads the changed infotons and creates the resulting materialized views. You configure both the change path and query and the SPARQL query that creates the materialized view.
You define the SPARQL Trigger Processor's input and output by editing a YAML-formatted configuration file.
Note
The SPARQL Trigger Processor also exists an external utility that you can run as a stand-alone executable. This page describes the SPARQL Trigger Processor integrated agent that runs within CM-Well. All you need to do in order to activate the agent for your materialized view is to define and upload the appropriate YAML configuration file.
See Using SPARQL on CM-Well Infotons to learn more about SPARQL queries.
Creating the YAML Configuration File¶
The SPARQL Trigger Processor's configuration file is in YAML format. It contains:
- A query for detecting changes in specified infotons and collecting data to process.
- A SPARQL query for processing the collected data and creating the materialized view.
The following table describes the parameters that you can configure in the YAML file:
| Parameter | Description |
|---|---|
| name | An informative name for this configuration. This should describe the materialized view you're creating. |
| sensors | In the sensors parameter, you can define one or more "sensors", that detect changes in fields that you define. For example, you may want to test for changes to organizations' names, then process those organizations whose names have changed. Multiple sensors are defined in the YAML list syntax (prefixed with a '-' character). |
| sensors/name | An informative name for the sensor, used in SPARQL Trigger Processor logs. |
| sensors/path | The path in CM-Well under which the sensor checks for changes. |
| sensors/qp | The query that the sensor runs to detect changes. |
| sensors/fromIndexTime | Optional. The Triggered Processor only looks at updates that were made after fromIndexTime. |
| sensors/token | Optional. A state token that indicates the time from which the sensor should start searching. You can use token as an alternative to fromIndexTime. |
| sensors/sparqlToRoot | Optional. A SPARQL query that operates on the output of the qp query. You can use this query to travel upward from a changed node to the affected entity, for which you want to create a materialized view. |
| sparqlMaterializer | A SPARQL query that processes the input data and constructs the materialized view. |
| updateFreq | The SPARQL processor runs on data that's been updated since the time defined in fromIndexTime, and until the present time. Then it pauses for the amount of time defined in updateFreq, then it runs again until it processes all new updates, and so on. The updateFreq value is formatted like a Scala Duration object (\<timeUnit> + '.' + \<unitNumber>). |
| hostUpdatesSource | Optional. The CM-Well host from which to read the infotons whose materialized view we're creating. If this parameter isn't defined, by default infotons are read from the host on which the STP is running. |
Note
Make sure to indent the file correctly, according to YAML syntax rules.
Here is a (truncated) example of the YAML configuration file:
updateFreq: 1.minute name: MyMaterializedView hostUpdatesSource: cm-well.myhost.com active: true sensors: - name: organization path: /data.com qp: type.rdf:http://oa.schemas.tfn.thomson.com/Organization/2010-05-01/OrganizationName fromIndexTime: 0 token: pAB6eJxVyzsOwjAQANHL0GY_hhApHQ1lOMP sparqlToRoot: | PATHS /data.com/2-%PID%?yg=<organizationName.oa&with-data&length=1000 SPARQL PREFIX oa: <http://oa.schemas.tfn.thomson.com/Organization/2010-05-01/> SELECT DISTINCT ?orgId WHERE { ?orgId oa:organizationName ?orgName . } sparqlMaterializer: | PATHS /data.com/1-%PID%?xg&yg=<identifierEntityId.metadata&length=1000 /data.com/1-%PID%?yg=<relatedFromEntityId.metadata|<relatedToEntityId.metadata /data.com/?op=search&qp=relatedFromEntityId.metadata:1-%PID%,relatedToEntityType.metadata:Geography&length=1000&with-data=true&yg=>relatedToEntityId.metadata<identifierEntityId.metadata /data.com/?op=search&qp=relationObjectId.metadata-new:1-%PID%,relationshipTypeId.metadata-new:310017&yg=>relatedObjectId.metadata-new<relationObjectId.metadata-new&with-data /data.com/1-%PID%?yg=<relatedObjectId.metadata-new[relationshipTypeId.metadata-new:310077]>relationObjectId.metadata-new<relatedFromEntityId.metadata[relationshipTypeCode.metadata:TRBCChildOf]>relatedToEntityId.metadata<relatedFromEntityId.metadata[relationshipTypeCode.metadata:TRBCChildOf] SPARQL prefix tr-org: <http://permid.org/ontology/organization/> prefix owl: <http://www.w3.org/2002/07/owl#> prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> prefix oa: <http://oa.schemas.tfn.thomson.com/Organization/2010-05-01/> prefix data: <http://data.com/> prefix vcard: <http://www.w3.org/2006/vcard/ns#> prefix xsd: <http://www.w3.org/2001/XMLSchema#> prefix ont: <http://ont.thomsonreuters.com/> prefix tr-common: <http://permid.org/ontology/common/> prefix md: <http://data.schemas.financial.thomsonreuters.com/metadata/2009-09-01/> CONSTRUCT { ?permId rdf:type tr-org:Organization . ?permId owl:sameAs ?cmpUri . ?permId vcard:hasURL ?url . ?permId tr-org:hasIPODate ?ipoDate . ?permId tr-org:hasOrganizationType ?optype . ?permId tr-org:hasActivityStatus ?statusOntologyTerm . ?permId ?foundedPredicate ?foundedDate . ?permId tr-org:hasHoldingClassification ?holding . ?permId tr-org:hasInactiveDate ?inactiveDate . ?permId tr-common:hasPermId ?permIdNumeric . ?permId tr-org:hasSubTypeCode ?subTypeCode . ?permId tr-org:isVerified ?verified . ?permId tr-org:isManaged ?isManaged . } WHERE { BIND(data:1-%PID% as ?cmpUri ) . ?cmpUri rdf:type oa:Organization . BIND(URI(REPLACE(STR(?cmpUri),"data.com","permid.org")) as ?permId) . ?cmpUri ont:permId ?permIdNumeric . ?cmpUri oa:isOrganizationManaged ?isManaged . ...
Querying for Multiple Parameters in the sparqlToRoot Query¶
In the sparqlToRoot SPARQL query defined in the STP sensor configuration, you can query for multiple parameters in the SELECT command. STP forwards the [key, value] pairs yielded by the sparqlToRoot query to the _sp materialization invocation as parameters.
For example, the sparqlToRoot query could include the following SELECT command:
SELECT ?languge, ?orgId, ?country WHERE { … }
Let’s say that for a certain path, the results were language=Japanese, orgId=613, country=Japan. Then the _sp invocation for materialization will be with the following query parameters:
/_sp?sp.language=Japanese&sp.orgId=613&sp.country=Japan
The sparqlMaterializer query might also include those variables in the body of the SPARQL CONSTRUCT request, like so:
… WHERE { ?cmpUri ont:locatedIn %country% ; ont:speaksLanguage %language% . } ...
Controlling the SPARQL Trigger Processor Job¶
Activating and Deactivating the Job¶
When you have created the YAML configuration file and are ready to apply it, you upload it to CM-Well at meta/sys/agents/sparql/<configName>, where the containing folder name \<configName\> is a unique name that describes your configuration.
Note
You will need special permissions to upload a file to the meta/sys folder.
Here is an example of a command that uploads a SPARQL configuration file:
curl -X POST "<cm-well-host>/meta/sys/agents/sparql/MyCompanyMaterializedView" -H "X-CM-WELL-TYPE: FILE" -H "Content-Type: text/yaml" --data-binary @my-config.yaml -H X-CM-WELL-TOKEN:<accessToken>
Uploading the configuration file causes CM-Well to read the file and run the SPARQL Trigger Processor agent on it. CM-Well polls periodically for changes to this file and applies the changes when they're detected.
If you want to stop the job and delete its configuration permanently, delete the configuration location, for example:
curl -X DELETE <cm-well-host>/meta/sys/agents/sparql/MyCompanyMaterializedView
Note
The job will end gracefully even without pausing it before deleting the configuration location.
Pausing and Restarting the Job¶
You can pause and restart the SPARQL job by changing a Boolean value under your configuration folder. If this flag doesn't exist, its default value is true.
To temporarily pause and restart the SPARQL job, you can toggle the value of this flag as follows.
Pause the job:
curl "<cm-well-host>/_in?format=ntriples&replace-mode" -H X-CM-WELL-TOKEN:<accessToken> --data-binary "
<cmwell://meta/sys/agents/sparql/MyCompanyMaterializedView> <cmwell://meta/nn#active> \"false\"^^<http://www.w3.org/2001/XMLSchema#boolean> .
"
Note
When you pause the SPARQL job, the last processed position is saved, and when you restart the job it resumes from the same position.
Restart the job:
curl "<cm-well-host>/_in?format=ntriples&replace-mode" -H X-CM-WELL-TOKEN:<accessToken> --data-binary "
<cmwell://meta/sys/agents/sparql/MyCompanyMaterializedView> <cmwell://meta/nn#active> \"true\"^^<http://www.w3.org/2001/XMLSchema#boolean> .
"
The SPARQL Trigger Processor Monitoring Page¶
In the SPARQL Trigger Processor monitoring page, you can view the status and processing metrics of all SPARQL agent jobs. To see the monitoring page, browse to proc/stp.md on the CM-Well host machine.
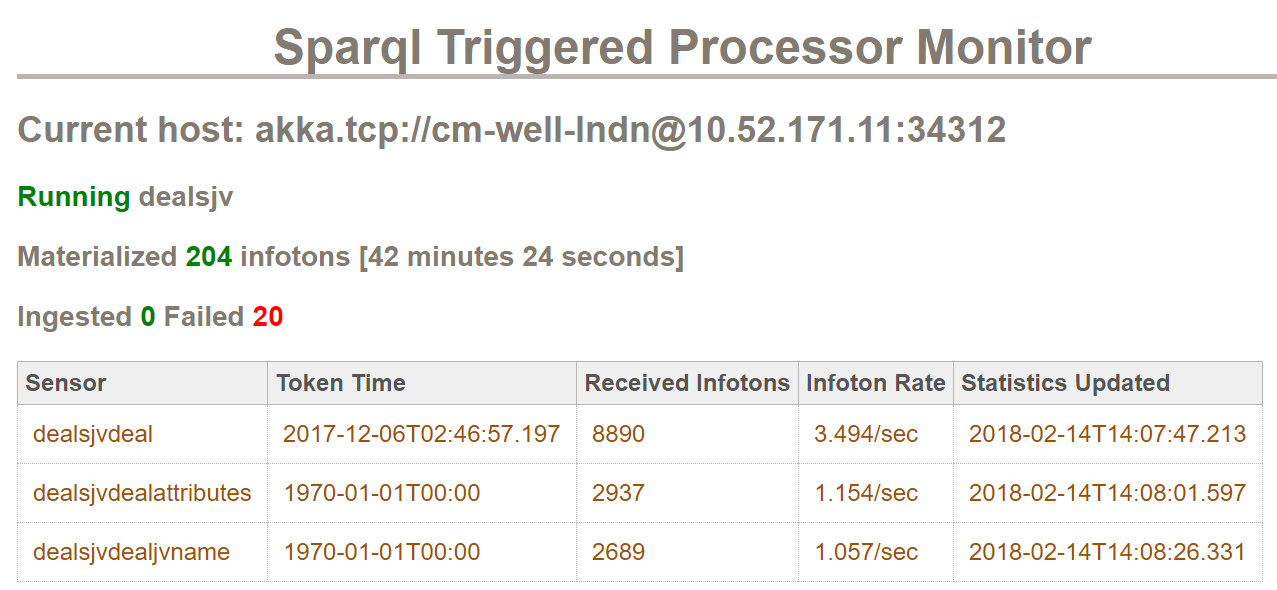
These are the details displayed in the table for each sensor:
Detail | Description |:------|:----------- Sensor | The sensor's name Token Time | The point in time that the sensor is currently processing Received Infotons | The number of changed infotons that the sensor detected Infoton Rate | The number of infotons that the sensor is processing per second. Statistics Updated | The time that the sensor made its latest update.
DEPRECATED: Downloading and Compiling CM-Well Data Tools¶
Note
- To access the CM-Well Git site, you will need a GitHub user. See the CM-Well GitHub Repository.
- To compile and run CM-Well data tools, you will need Java version 8.
To download and compile the CM-Well Data Tools source code:
- Go to http://www.scala-sbt.org/download.html and install the Scala Build Tool (SBT) version appropriate for your OS.
- Add the Scala sbt command to your PATH variable.
- Perform a Git clone of the CM-Well Data Tools source code from https://github.com/CM-Well/CM-Well.
- Navigate to the
cm-well/cmwell-data-tools/tree/masterfolder. It contains a file called build.sbt. - Run the following command:
sbt app/pack. The resulting script executables are created in thecmwell-data-tools-app/target/pack/binfolder.
Note
To compile and run the CM-Well data tools, you will need Java version 8.
DEPRECATED: Running the SPARQL Trigger Processor Utility¶
You can still run the SPARQL Trigger Processor as a stand-alone executable.
To run the SPARQL Trigger Processor, run cmwell-data-tools\cmwell-data-tools-app\target\pack\bin\sparql-processor-agent on a Unix machine or cmwell-data-tools\cmwell-data-tools-app\target\pack\bin\sparql-processor-agent.bat on a Windows machine.
Example:
cmwell-data-tools-app/target/pack/bin/sparql-processor-agent --source-host cm-well-prod.int.thomsonreuters.com --config sensors.yaml --state state.dat --bulk
The following table describes the SPARQL Trigger Processor's input parameters:
| Parameter | Description |
|---|---|
| -b, --bulk | Use the bulk-consumer mode for download |
| -c, --config |
The path to the sensor configuration file |
| -s, --source-host |
The source CM-Well host server, from which data is read |
| -i, --ingest | A flag that indicates whether to ingest the processed data to a CM-Well instance |
| -d, --dest-host |
If ingest is indicated, the -d parameter defines the destination CM-Well instance, to which the processed data is written. |
| --state |
A path to the token file that encodes the consume state for all sensors. To save the token file the first time you run the Triggered Processor, provide a path to the file. The Triggered Processor writes new state tokens to this file as chunks are consumed. To start the processing where you left off, you can use the state file saved from a previous run of the agent as input the next time you run it. |
| -w, --write-token |
The CM-Well write permission token |
| --help | Show the help message |
| --version | Show the version of this application |
Note
- To display a description of the SPARQL Trigger Processor parameters, run
sparql-processor-agent --help. - There are 3 ways you can provide a start time for the sensor queries. In descending order of precendence, these are:
- The token file provided as the tool's state parameter.
- The sensors/token parameter in the YAML configuration file.
- The sensors/fromIndexTime parameter in the YAML configuration file.