Preface¶
Scope¶
This page is your entry point for learning about the CM-Well internal architecture. Typically it will be of interest to developers who want to understand and contribute to the CM-Well code base.
What is CM-Well?¶
CM-Well is a writable Linked Data repository, which you can use to model data. CM-Well adheres to Open Data principles, meaning that its data is in a standard, machine-readable format. The CM-Well code is open source and is available at GitHub.
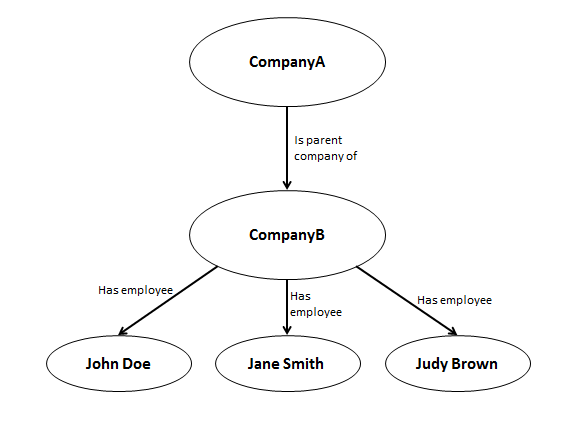
CM-Well's data is represented as a graph database, which means that it contains entities and relationships between pairs of entities. For instance, it might contain facts such as "CompanyA is a subsidiary of CompanyB" or "PersonX works at CompanyA". Conceptually, a graph database is a structure composed of nodes representing entities, and directed arrows representing relationships among them. See the image below for an example.
Terms and Abbreviations¶
| Term | Description |
|---|---|
| BG | Background module |
| CAS | Cassandra storage package |
| DC | Data Center |
| DCC | Data Consistency Crawler agent |
| DC-Sync | Data Center Synchronization |
| ES | ElasticSearch indexing and search package |
| GS-Logic | Grid Storage Logic module |
| FTS | Full Text Search |
| IMP | Infoton Merge Process |
| JVM | Java Virtual Machine process |
| KF | Kafka module |
| SPoF | Single Point of Failure |
| STP | SPARQL Trigger Processor |
| URI | Uniform Resource Identifier |
| UUID | Universally Unique Identifier |
| WS | Web Service module |
| ZK | Zookeeper module |